



Dans l’analyse statistique, le niveau de mesure des variables est crucial car il influence le type d’analyse possible. Les données nominales sont les moins détaillées, tandis que les données d’intervalle et de rapport sont les plus détaillées ; ces différences reflètent les différences entre les quatre principaux niveaux de mesure (nominal, ordinal, intervalle et rapport).
APPRENEZ-EN DAVANTAGE SUR LE SUJET : Niveau d’analyse
Pour comprendre les principes fondamentaux des données nominales, c’est ici qu’il faut se rendre. Dans ce blog, nous examinerons les bases de cette analyse de données, y compris ce qu’elle est, comment l’identifier et quelques exemples.
Qu’est-ce qu’une donnée nominale ?
Les données nominales sont des données « étiquetées » ou « nommées » qui peuvent être divisées en différents groupes qui ne se chevauchent pas. Dans ce cas, les données ne sont ni mesurées ni évaluées ; elles sont simplement assignées à plusieurs groupes. Ces groupes sont uniques et n’ont pas d’éléments communs.
L’ordre des données collectées ne peut être établi à l’aide de données nominales ; par conséquent, si vous changez l’ordre des données, la signification des données ne sera pas modifiée.
Dans la nomenclature latine, « Nomen » signifie – Nom. Les données nominales présentent une similitude entre les différents éléments, mais les détails de cette similitude peuvent ne pas être divulgués. Il s’agit simplement de faciliter le processus de collecte et d’analyse des données pour les chercheurs. Dans certains cas, elles sont également appelées « données catégorielles ».
Si les données binaires représentent des données « à deux valeurs », ces données représentent des données « à plusieurs valeurs » et ne peuvent pas être quantitatives. Il est considéré comme discret. Par exemple, un chien peut être un Labrador ou non.
En savoir plus : L’échelle nominale
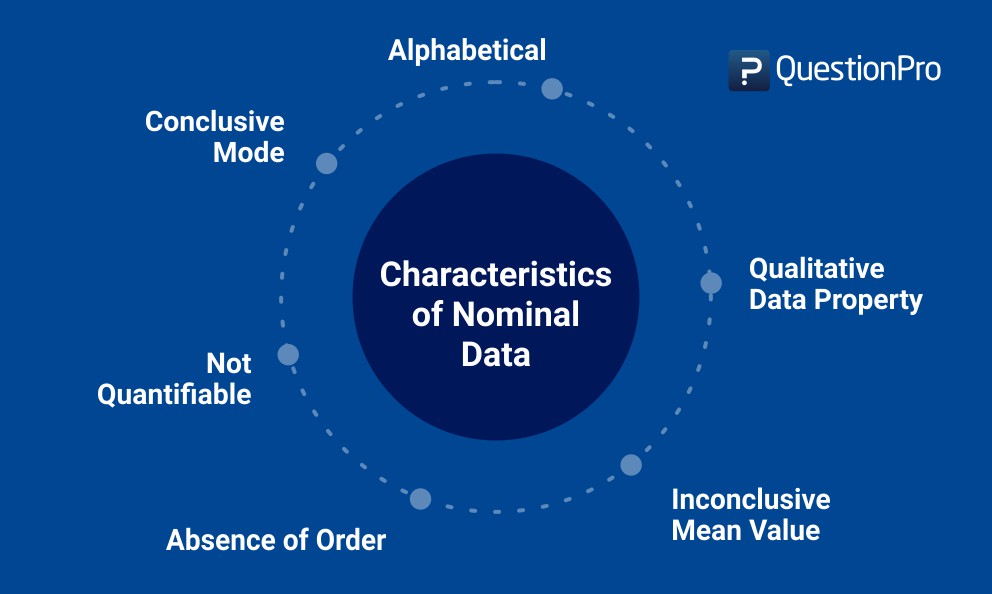
Caractéristiques des données nominales
Discutons des caractéristiques des données nominales à l’aide de cette question :
- Q. Quelle est votre origine ethnique ?
- Asie centrale
- Indonésien
- Asie occidentale
- Japonais
Aujourd’hui, ses principales caractéristiques sont les suivantes :
- Les données nominales ne peuvent jamais être quantifiées : Elles se présenteront toujours sous la forme d’une nomenclature, c’est-à-dire qu’une enquête envoyée aux pays asiatiques peut comporter une question telle que celle mentionnée dans ce cas.
Dans ce cas, l’analyse statistique, logique ou numérique des données n’est pas possible, c’est-à-dire qu’un chercheur ne peut pas additionner, soustraire ou multiplier les données collectées ou conclure que la variable 1 est supérieure à la variable 2. - Absence d’ordre : Contrairement aux données ordinales, les données nominales ne peuvent jamais être classées dans un ordre précis. Dans l’exemple ci-dessus, l’ordre des options de réponse n’a aucune incidence sur les réponses fournies par le répondant.
- Propriété qualitative : Les données collectées auront toujours une propriété qualitative – les options de réponse sont très susceptibles d’être de nature qualitative.
- Impossible de calculer la moyenne : La moyenne ne peut être établie même si les données sont classées par ordre alphabétique. Dans l’exemple susmentionné, il est impossible pour un chercheur de calculer la moyenne des réponses soumises pour les ethnies en raison de la nature qualitative des options.
- Conclure à un mode : Si l’on demande à un large échantillon d’individus d’indiquer leurs préférences, la réponse la plus fréquente sera le mode. Dans l’exemple donné, si le japonais est la réponse soumise par une grande partie de l’échantillon, il s’agira du mode.
- Les données sont essentiellement alphabétiques : dans la plupart des cas, les données nominales sont alphabétiques et non numériques – par exemple, dans le cas mentionné. Les données non numériques peuvent également être classées en plusieurs catégories.
En savoir plus : Données quantitatives
Analyse des données nominales
La plupart des données nominales sont collectées par le biais de questions qui proposent au répondant une liste d’éléments à choisir, par exemple :
- Q1. Dans quel État habitez-vous ? ____ (suivi d’une liste déroulante d’États)
- Q2. Parmi les éléments suivants, lesquels choisissez-vous habituellement pour garnir votre pizza ? (Cochez toutes les cases correspondantes)
- Épinards
- Pepperoni
- Olives
- Sardines
- Saucisse
- Fromage supplémentaire
- Oignons
- Tomates
- Autre (veuillez préciser) _______________
Les données nominales peuvent être collectées de trois manières différentes. Dans le premier exemple, le répondant dispose d’un espace pour écrire son État de résidence. Il s’agit d’une question ouverte qui sera ensuite codée, chaque État se voyant attribuer un numéro. Ces informations peuvent également être fournies au répondant sous la forme d’une liste, dans laquelle il doit choisir une option.
Le deuxième exemple se présente sous la forme de questions à réponses multiples où chaque catégorie est codée 1 (si elle est sélectionnée) et 0 si elle n’est pas sélectionnée. Il comporte également une partie ouverte qui permet au répondant d’écrire dans une catégorie qui ne figure pas dans la liste. Ces réponses « Autres (veuillez préciser) » devront être codées si elles doivent être analysées.
Les données nominales sont analysées à l’aide de pourcentages et du « mode », qui représente la ou les réponses les plus courantes. Pour une question donnée, il peut y avoir plus d’une réponse modale, par exemple si les olives et la saucisse ont été choisies le même nombre de fois.
Les questions à réponses multiples, comme l’exemple de la garniture de pizza cité plus haut, permettent aux chercheurs de créer une variable métrique qui peut être utilisée pour des analyses supplémentaires. Dans ce scénario, le répondant peut sélectionner n’importe quelle option ou toutes les options, ce qui vous donne une variable allant de zéro (aucune option sélectionnée) au nombre maximum de catégories. Cela devient un outil utile pour la segmentation comportementale des consommateurs.
En savoir plus : Segmentation du marché

Statistiques descriptives
La distribution des données peut être déterminée à l’aide de statistiques descriptives. Nous pouvons utiliser deux méthodes de statistiques descriptives pour ces données :
- Tableau de distribution de fréquences : Ce tableau est conçu pour organiser les données nominales dans un certain ordre. Ce type de tableau permet de voir facilement le nombre de réponses pour chaque catégorie de la variable.
- Tendance centrale : C’est ce que l’on appelle communément le mode. Il permet de mesurer où se trouve la majorité des valeurs. Cependant, un seul mode peut être estimé pour ces données car elles ne sont que qualitatives.
APPRENDRE À CONNAÎTRE : L’analyse descriptive
Analyse graphique
L’analyse graphique consiste à présenter l’ensemble des données sous une forme visuelle. Comme les statistiques descriptives, la visualisation de vos données vous permet de voir plus facilement ce qu’elles révèlent. Ces méthodes peuvent être utilisées sur l’ensemble des données du tableau et sur un échantillon de celles-ci.
- Diagramme à barres : La fréquence de chaque réponse est représentée graphiquement sous la forme d’une barre s’élevant verticalement à partir de l’axe horizontal dans un diagramme à barres, qui est le plus souvent utilisé. La hauteur de chaque barre est inversement corrélée à la fréquence de la réponse correspondante.
- Diagramme circulaire : La fréquence en pourcentage de chaque échantillon de l’ensemble de données nominales peut être représentée par un diagramme circulaire, qui est également utilisé.
Le chercheur utilise généralement un diagramme circulaire pour représenter les pourcentages (ou fractions), tandis qu’un diagramme à barres est généralement utilisé pour représenter les fréquences de distribution (mode).
Catégorisation des données nominales
Les données nominales nécessitent une catégorisation basée sur les similitudes et les différences pour être correctement analysées. Cette méthode permet aux chercheurs de comparer les résultats de leurs recherches en les associant à une collection similaire de données qui n’a pas été étudiée.
- Catégorie appariée : Les échantillons provenant du même ensemble de variables de données nominales sont regroupés dans la catégorie appariée. L’amélioration des résultats statistiques est l’objectif principal de l’appariement, qui est réalisé en réduisant l’influence des facteurs de confusion.
- Catégorie non appariée : Les échantillons non appariés contiennent des variables qui ne sont pas reliées entre elles. Il s’agit d’une sélection aléatoire de plusieurs ensembles de données différents sans aucun point commun.
Tests statistiques
Les tests statistiques permettent de vérifier une hypothèse en approfondissant les informations révélées par les données, alors que les statistiques descriptives, l’analyse graphique et la catégorisation ne font que résumer les données nominales en vue d’une analyse directe. Dans l’analyse statistique, il est essentiel de faire la distinction entre les données catégorielles et les données numériques, car les données catégorielles impliquent des catégories ou des étiquettes distinctes, tandis que les données numériques consistent en des quantités mesurables.
Pour les données nominales et ordinales, des tests statistiques non paramétriques sont utilisés. Par conséquent, vous pouvez effectuer le test du khi-deux lorsque vous examinez un ensemble de données nominales :
- Test d’adéquation du chi carré : Ce test détermine si l’échantillon de données est représentatif de l’ensemble de la population de données. Le test est appliqué lorsque les informations sont recueillies par échantillonnage aléatoire à partir d’une population unique.
- Test d’indépendance du khi-deux : Ce test examine la relation entre deux variables nominales. Le test d’hypothèses permet de déterminer l’indépendance de deux variables nominales à partir d’un seul échantillon.
Exemples de données nominales
Dans chacun des exemples mentionnés ci-dessous, des étiquettes sont associées à chacune des options de réponse uniquement dans le but de les étiqueter. Par exemple, dans la première question, des numéros sont attribués à chaque race de chien, tandis que dans la deuxième question, des initiales correspondantes sont attribuées aux deux sexes, uniquement pour des raisons de commodité.
- Q1. Aux États-Unis, un grand nombre de personnes aiment les chiens et en possèdent. Pour une entreprise qui s’occupe de prendre soin des chiens en l’absence de leurs propriétaires, une question comme celle-ci peut être utile pour filtrer son marché cible : Quelle est la race de chien la plus appréciée ?
- Dalmatien – 1
- Doberman – 2
- Labrador – 3
- Berger allemand – 4
- Q2. Pour une agence de voyage qui cherche à lancer un plan de voyage uniquement pour un échantillon d’individus, c’est la question la plus élémentaire : Qui aime le plus voyager ?
- Hommes – M
- Femmes – W
- Q3. Un agent immobilier basé à New York sera très enclin à comprendre la réponse à cette question : Quels sont les types de maisons préférés des habitants de la ville de New York ?
- Appartements – A
- Bungalows – B
- Villas – C
En savoir plus : Les types d’échelles de mesure variables
Utilisation de QuestionPro Research Suite pour la collecte et l’analyse de données nominales
QuestionPro Research Suite est une plateforme pour les enquêtes et la recherche qui peut être utilisée pour examiner des données nominales. La plateforme offre de nombreuses fonctionnalités et outils pour l’analyse des données, tels que
- Types de questions : Les types de questions, y compris les questions à sélection unique, les questions à sélection multiple et les questions ouvertes, sont disponibles dans QuestionPro et peuvent être utilisées pour recueillir des données nominales.
- Collecte des données : QuestionPro offre une variété d’options de collecte de données, y compris des enquêtes par Internet, des invitations par courrier électronique et des enquêtes mobiles.
- Visualisation des données : La plateforme offre des possibilités de visualisation interactive des données, telles que des diagrammes à secteurs et des graphiques à barres.
- Analyse des données : Le module d’examen des données intégré à QuestionPro offre des statistiques descriptives pour l’analyse des données nominales, y compris la distribution des fréquences et des pourcentages.
- Segmentation : La plateforme dispose de fonctions de segmentation qui permettent aux utilisateurs de diviser les données nominales en groupes sur la base de divers traits de segmentation démographiques, comportementaux ou psychographiques.
- Rapports : QuestionPro propose des rapports personnalisables pour résumer et partager les résultats avec les décideurs.
Utilisez QuestionPro Research Suite pour collecter et analyser des données nominales afin de mieux connaître votre public. Notre plateforme vous permet de créer et de diffuser des enquêtes démographiques en ligne pour recueillir des informations sur l’âge, le sexe, l’éducation, la profession, etc. Nos outils de visualisation des données et notre module d’analyse des données vous aideront à interpréter immédiatement les résultats.
EN SAVOIR PLUS : Valeur moyenne des commandes
Profitez de cette occasion pour améliorer vos compétences en matière de recherche et atteindre vos objectifs. Commencez votre voyage d’analyse des données nominales dès maintenant avec un essai gratuit !



