



名目上のデータ定義
ノミナルデータとは、重複しない様々なグループに分けられる「ラベル付け」または「名前付け」されたデータのことである。 この場合、データは測定も評価もされず、ただ複数のグループに割り振られるだけです。 これらのグループはユニークであり、共通する要素はない。 ノミナルデータでは、収集したデータの順番を確定することができないため、データの順番を変えてもデータの意味は変わりません。
ラテン語の命名法では、「Nomen」は「名前」を意味します。 名目上のデータは各項目の類似性を示すが、その類似性の詳細については開示されない場合がある。 これは、研究者がデータ収集や分析作業をしやすくするために過ぎない。 場合によっては、ノミナルデータを「カテゴリーデータ」とも呼ぶ。
二値データが「二値」のデータを表すとすれば、ノミナルデータは「多値」のデータを表し、定量的であるはずがないのです。 名目データは離散的であると考えられる。 例えば、犬はラブラドールであってもなくてもいい。
について学ぶ。
ノミナルスケール
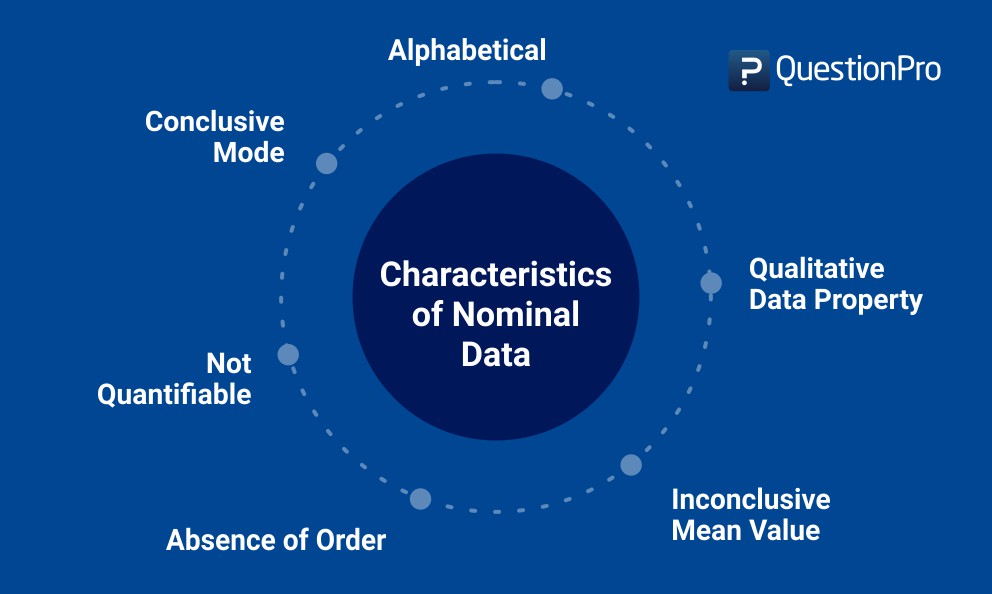
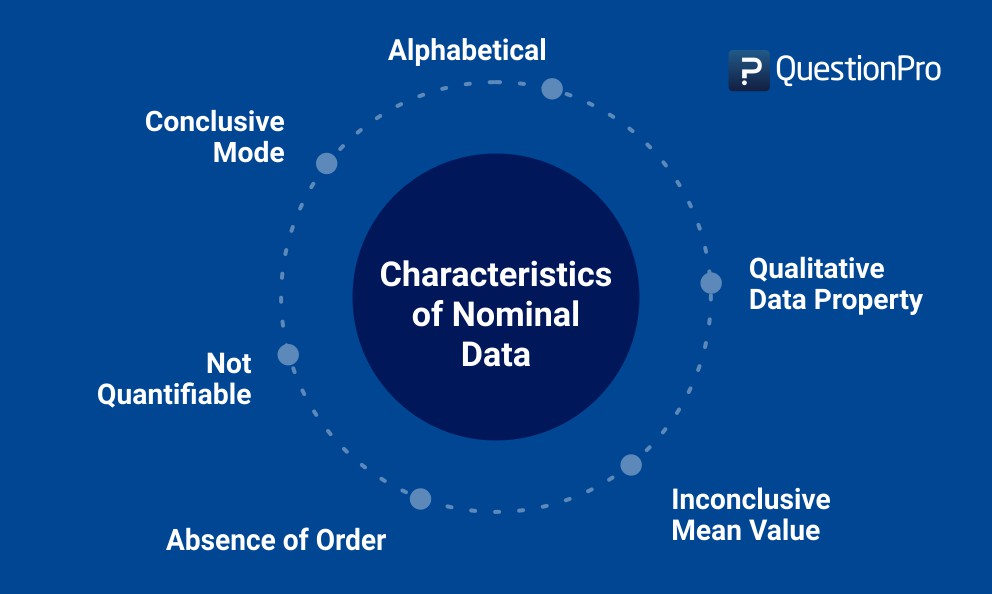
ノミナルデータの特徴
この問題を用いて、ノミナルデータの特徴について説明しましょう。
あなたの民族性は? –
- 中央アジア
- インドネシア語
- 西アジア
- やまと
- 名目上のデータは決して数値化できない。 名目データは常に命名法の形式をとる。例えば、アジア諸国に送る調査には、今回述べたような質問が含まれることがある。 つまり、研究者は収集したデータの足し算、引き算、掛け算ができないし、変数1が変数2より大きいと結論づけることもできないのである。
- 順序の不存在。 序数データとは異なり、名目データには明確な順序が与えられない。 上記の例では、回答の選択肢の順番は、回答者が提供する回答とは無関係です。
- 質的な性質。収集されたデータは常に定性的な性質を持っている – 回答の選択肢は定性的な性質を持っている可能性が高い。
- 平均値の計算ができない。 名目データの平均は、データをアルファベット順に並べたとしても、確定することはできない。 上記の例では、選択肢が質的なものであるため、調査者が民族別に提出された回答の平均値を算出することは不可能です。
- モードを完成させる。 大量のサンプルを使って個人の好みを提出してもらう – 最も多い回答はモードである。 この例では、日本語がより多くのサンプルによって提出された回答であれば、それが最頻値となる。
- データはほぼアルファベット順です。 ほとんどの場合、名目データはアルファベットで、数値ではありません – たとえば、前述のような場合です。 非数値データも様々なグループに分類することができる。
詳細はこちら
定量的データ
ノミナルデータ解析
ほとんどの名目データは、例えば、回答者に選択する項目のリストを提供する質問によって収集されます。
お住まいの州はどちらですか? ____ (その後に州のドロップダウンリストが続きます。)
あなたが普段ピザのトッピングに選んでいるのは次のうちどれですか? (該当するものをすべて選択してください)
1)ホウレンソウ
2)ペパロニ
3) オリーブ
4)イワシ
5)ソーセージ
6)エクストラチーズ
7)玉ねぎ
8)トマト
9)その他(具体的にご記入ください) ______________
ノミナルデータの収集方法には、3つの方法があります。 最初の例では、回答者に出身州を記入する欄が与えられています。 これは自由形式の質問で、最終的には各州に番号が割り当てられてコード化される形になっています。 この情報は、リストの形で回答者に提供し、回答者が選択肢を1つ選ぶという方法もあります。
2つ目の例は、各カテゴリーを選択した場合は1、選択しない場合は0とする複数回答形式の質問です。 また、回答者がリストに含まれていないカテゴリーを記入できるよう、自由記述欄が設けられています。 これらの「その他」の回答は、分析する場合にはコーディングが必要です。
名目データは、パーセンテージと最も一般的な回答を表す「最頻値」を使用して分析されます。 例えば、オリーブとソーセージが同じ回数だけ選択された場合、一つの質問に対して、複数のモーダル回答が存在する可能性があります。
複数回答の質問、例えば上記のピザのトッピングの例では、研究者は追加分析に使用できるメトリック変数を作成する能力を持つことができます。 このシナリオでは、回答者は任意またはすべてのオプションを選択することができ、ゼロ(何も選択されていない)から最大数のカテゴリまでの範囲の変数を得ることができます。 これは、消費者セグメンテーションに有効なツールとなる。
ノミナルデータは、回答者のプロファイリングに最適です。 この種のデータは統計的な能力に限界がありますが、アンケート回答者をより深く理解するためには重要です。 次に、順序データについて考察する。
公称データ例
後述の各例では、各回答選択肢にラベルを貼る目的でのみラベルが関連付けられています。 例えば、1つ目の質問では犬種ごとに番号をつけ、2つ目の質問では便宜上、性別ごとにイニシャルをつけました。
- アメリカでは、犬が好きで飼っている人が非常に多い。 留守中の犬の世話をする会社にとって、ターゲットを絞り込むのに有効な質問です。最も愛されている犬種は? –
- ダルメシアン – 1
- ドーベルマン – 2
- ラブラドール – 3
- ジャーマンシェパード – 4
- 純粋に個人のサンプルとして旅行プランを立ち上げようとする旅行会社にとって、これは最も基本的な質問である。誰がもっと旅行が好きなのか? –
- 男性 – M
- 女性 – W
- ニューヨークを拠点とする不動産業者は、この問いに対する答えを理解することに高い関心を持つだろう。ニューヨークの住人は、どのようなタイプの家を好むのでしょうか? –
- アパートメント – A
- バンガロー – B
- ヴィラ – C
について学びます。
変数測定尺度の種類



