クラスター・サンプリング:定義、方法、例
Reading Time: < 1 minute read クラスター・サンプリングとは、ある母集団 […]
Reading Time: < 1 minute read クラスター・サンプリングとは、ある母集団 […]
Reading Time: < 1 minute read 市場調査やデータ収集において、リサーチパ […]
Reading Time: < 1 minute read オンライン・アンケート・パネルの話題とは […]
Reading Time: < 1 minute read 特に、収集したデータをマーケティングの世 […]
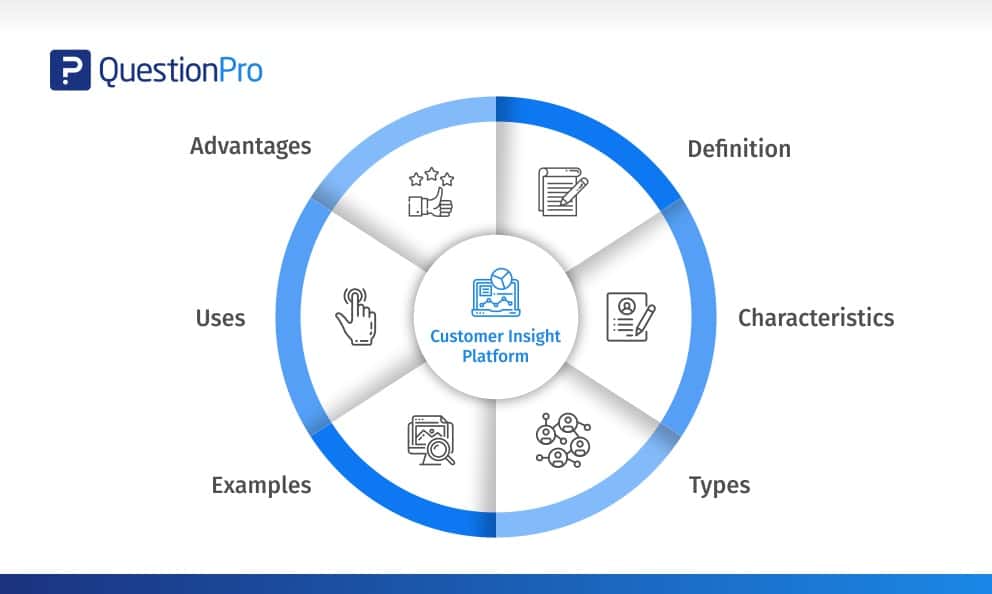
Reading Time: < 1 minute read カスタマーインサイトプラットフォーム。定 […]